为什么要用OpenCV?
丰富、高效的传统算法(视频分析、3D 重建、光流算法,不用自己写)
端到端的IO(从摄像头读入、显示屏输出,不用自己写)
CPU、(GPU)、VPU加速效果好(OpenVINO 对 CPU 加速效果还挺明显的)
如果你的研究涉及到具体的应用实现的话,OpenCV 会减少一些开发 Demo 的工作量。我校的视觉所,在做生物特征工程(人脸识别、指纹识别等等)相关研究的时候,因为研究涉及的流程长(感知、预处理、特征提取、特征检索等等)又必须有个 Demo ,用 OpenCV 就会减少很多工作量。
安装
直接 brew 指定版本安装
先更新一下 brew(不必要):
brew update安装所需依赖(不必要):
brew install cmake boost tbb指定 4.0 版本安装 OpenCV,如果不指定的话默认是opencv3:
brew install opencv@4配置 Xcode 环境
C++ 是一门比较麻烦的语言,#include 进来的东西,编译链接的时候要自己配置好路径。当前文件夹下自己写的东西、系统的基础库还好说(因为已经默认了),像 OpenCV 这种下载的就得自己配置了。所以单独出一个部分讲解一下 Xcode 如何配置环境。
首先,新建一个命令行应用。
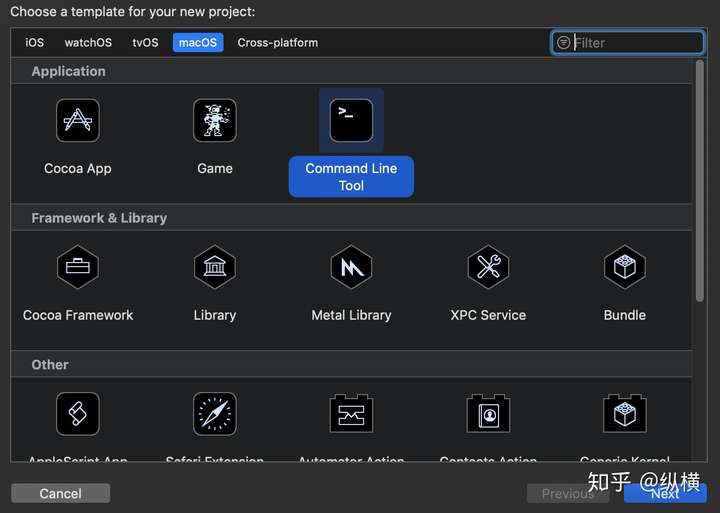
Xcode 默认推荐使用 swift,虽然我们可以用 swift 再去调用 C++,这里就简单一点,直接勾选 C++ 语言。
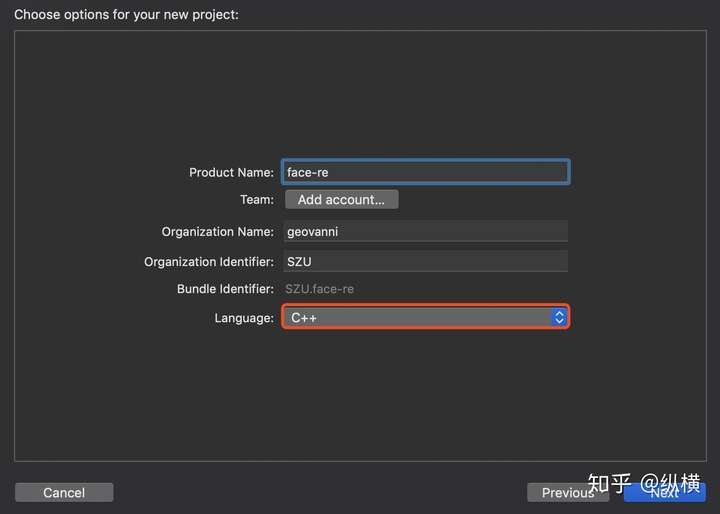
点击项目,选择 Build Settings 选项卡,使用搜索框搜索 search,修改 Header Search Paths 和 Library Search Path。这样,Xcode 在编译 C++ 文件时,如果找不到头文件或者库文件就会去我们设置的目录下索引。
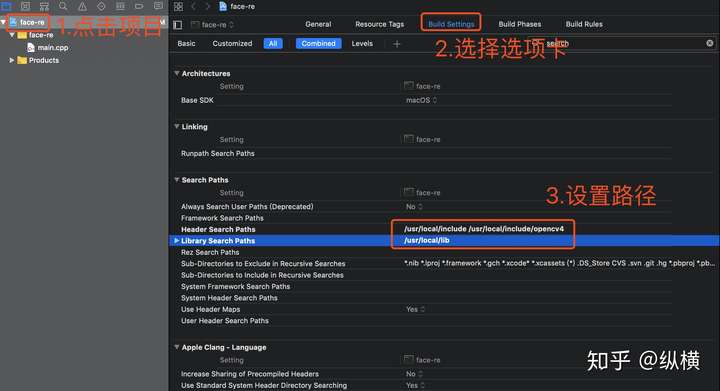
强调一下,这里的 Header Search Path 和 OpenCV3 是不同的,OpenCV3 默认的头文件文件夹是 opencv,而 OpenCV4 的是 opencv4。
Header Search Path:
/usr/local/include
/usr/local/include/opencv4
Library Search Path:
/usr/local/lib点击项目,选择 Build Phases 选项卡,添加库文件。
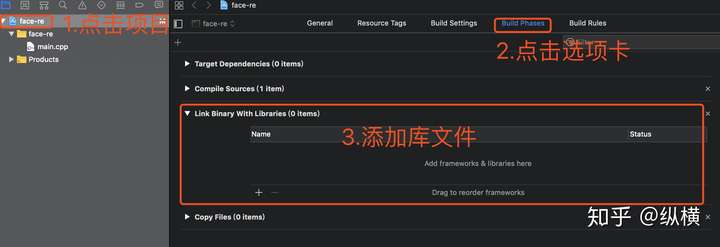
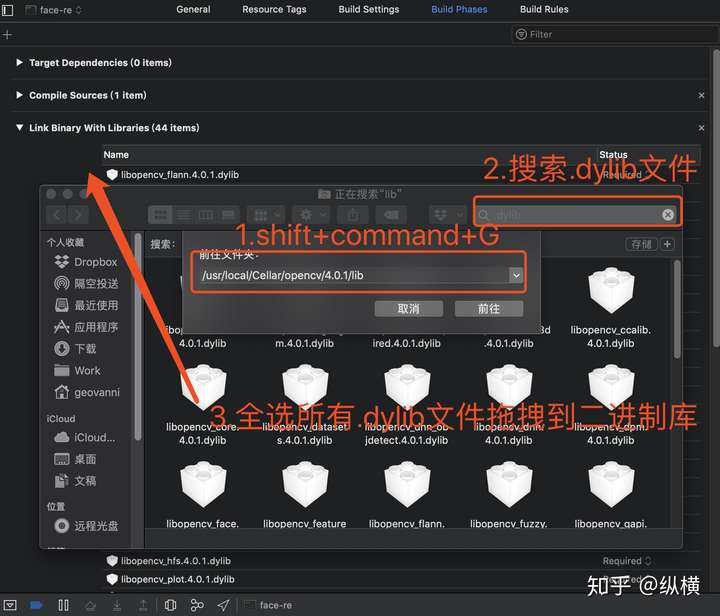
我们可以使用 Finder 找到 OpenCV 的二进制库文件。首先打开 Finder,按下 Shift + command + G,输入路径 /usr/local/Cellar/opencv/4.0.1/lib(这是 brew 安装 OpenCV 的默认地址,如果版本不一样可以找一下)并跳转(因为默认这些目录是不显示的,只能用这种方法啦)。最后,搜索文件夹下的所有 .dylib 文件,拖入 xcode 的二进制库选项卡~
现在可以粘贴测试代码运行一下项目:
//
// main.cpp
// face-re
//
// Created by geovanni on 2019/1/14.
// Copyright © 2019 geovanni. All rights reserved.
//
#include
#include
#include
#include
using namespace cv;
using namespace std;
// 视频来源于摄像头
VideoCapture capture(0);
Mat edges;
int main(int argc, const char * argv[]) {
while (true) {
Mat frame;
// 每一帧
capture >> frame;
// 转为灰度图
cvtColor(frame, edges, COLOR_BGR2GRAY);
blur(edges, edges, Size(7, 7));
Canny(edges, edges, 0, 30, 3);
// 边缘检测并显示边缘
imshow("Read Video", edges);
// 等待用户输入
if(waitKey(30) >= 0) break;
}
return 0;
} 编译运行一下,你会发现可以编译,但是运行时报错了~
This app has crashed because it attempted to access privacy-sensitive data without a usage description. The app's Info.plist must contain an NSCameraUsageDescription key with a string value explaining to the user how the app uses this data.这是 mbp 的安全策略导致的,要调用用户的摄像头,必须提示一个弹窗获得用户同意。在项目目录下的 build/Debug 下建立一个 Info.plist 文件,进行声明:
NSCameraUsageDescription
NSCameraUsageDescription 再次编译运行,运行成功。

使用 CMake
使用 cmake + vs code 写 C++。

我个人比较偏爱这样的目录结构(受 node 的影响叭)。build 用来放构建相关的文件,dist 用来放生成的二进制文件,src 用来放源文件。CMakeLists.txt 负责声明各种依赖,make.sh 负责各种附加选项。
main.cpp 的内容与上文相同,不再赘述。CMakeLists.txt 就是简单的引入 OpenCV 就好啦~
# CMake 版本号
cmake_minimum_required(VERSION 3.5)
# 项目名称
PROJECT(face-re)
# 二进制文件
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ./dist)
# 引入 OpenCV 包
find_package(OpenCV REQUIRED)
# 头文件
include_directories(${OpenCV_INCLUDE_DIRS})
# 可执行文件和源文件
add_executable(main src/main.cpp)
# 库文件
link_directories(${OpenCV_LIBRARY_DIRS})
target_link_libraries(main ${OpenCV_LIBS})另外,OpenCV 要求必须使用 C++11,所以我们在 make.sh 中要这样写:
cmake . -DCMAKE_BUILD_TYPE=Release -DBLAS="Open" -Dpython_version=3 -DCUDA_HOST_COMPILER=/usr/bin/g++-5 -DCUDA_PROPAGATE_HOST_FLAGS=off -DCMAKE_CXX_FLAGS="-std=c++11"
make编译链接好之后用命令行打开就好啦,注意这里 vscode 的 terminal 有点小坑,如果懒得调试可以直接使用系统的 terminal 或者 iterm:
./dist/mainOpenCV 基础知识
模块
#include <opencv2/core.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>这三个模块几乎每个项目都会用,其中:
- core 模块 —— 核心库,数据结构和基本运算
- highgui 模块 —— IO库,视频和图像的读入和显示
- imgproc 模块 —— 插件库,和图像有关的大部分都有,比如滤波器、图像变换之类的
其他的模块除了预处理一下数据集或者临时做个 Demo,我基本没用到过:video用来做视频处理;objdetect用来做目标检测;photo用来做图像修复等等。还有一些更小众的,用到的时候去查一下就好了~另外,除了 OpenCV 库中的模块,还有一些周边库也为 OpenCV 提供了支持:
- opencv_contrib —— 试用的功能
- training_toolbox_tensorflow —— 再训练 open_model_zoo 中的模型
数据类型
在引入 core 模块后,我们可以使用下面的数据类型描述数据,其中最重要、最常用的是 Mat:
Mat 是 OpenCV 中用来表示图像的多维数组,类似 tensorflow 和 pytorch 中的 tensor。
Mat src = imread(filepath);其他的数据类型都是配合 Mat 完成某种特殊任务的,比如 Rect 可以用来从 Mat 上选取目标等等。在使用过程中只要查找文档中相关任务的介绍,很快就会上手这些数据类型:Range 和 python 中的 range 一样,作为一个连续子序列。Vec 和 python 中的 list 一样,作为一个一维数组。Size 一个大小,具有 width, height 长宽的属性,表示图像或区域的大小。Point 一个点,具有 x,y 的属性,表示点的坐标。Rect 一个矩形,具有 x,y 左上角坐标和 width, height 长宽的属性。
基本操作
这里简单介绍三个主要模块提供的功能,这些功能完成了图像的输入、处理和输出。复杂的模块可以看作 imgproc 的拓展,封装了更为复杂的图像处理内容。
在引入 highgui 模块后,我们可以进行图像、视频的 IO 操作:
// 读入图像
Mat image = imread("file path");
// 创建窗口
namedWindow("window name", WINDOW_AUTOSIZE);
// 显示图像
imshow("window name", image);
// 保存图像
imwrite("file path", image);
// 销毁窗口
destroyAllWindows()
// 等待按键,0代表无限等待
waitKey(0)core 模块为数据类型提供了加减乘除等基本操作:
Mat image_1 = ...
Mat image_2 = ...
Mat image_3 = (image_1 + image2) * 3imgproc 模块提供了一些更复杂的图像变换操作:
// 将图像 image 转为灰度图赋值给 result
cvtColor(image, result, COLOR_BGR2GRAY);
// 将图像 image 翻转赋给 result
flip(image, result, 0);
// 将 image 缩放为 size 的大小并赋值给 result
resize(image, result, Size(...),0,0,INTER_LINEAR);神经网络
OpenCV 提供的神经网络接口和 keras 很像,经过高层次封装之后,用户只需要在网络实例上设置参数即可,使用简单,几乎没有什么灵活性。
在使用前初始化网络,设置使用的设备,这部分参数在 4.0 略有变化,因此放到后面详细说明:
Net net = readNet(model, config, framework);
net.setPreferableBackend(backendId);
net.setPreferableTarget(targetId);将输入图片进行预处理,转换为网络可以接受的数据格式 —— blob:
blobFromImage(frame, blob, scale, Size(inpWidth, inpHeight), mean, swapRB, false);设置神经网络的输入数据:
net.setInput(blob);进行前向传播:
Mat prob = net.forward();得到预测结果:
Point classIdPoint;
double confidence;
minMaxLoc(prob.reshape(1, 1), 0, &confidence, 0, &classIdPoint);
int classId = classIdPoint.x;如果你想阅读全部代码,可以查看官方文档的实例。
OpenCV4.0 的变化
移除 API
OpenCV 的历史包袱一直比较重,这次发版废除了一些 OpenCV1.0 的 API。值得一体的是,OpenCV 更新还是比较快的,所以新代码和旧代码都杂糅在一起,学习的时候尽量学新的,工作的时候尽量重构旧的,不一定什么时候旧废弃一部分。
这里萌新(尤其是赶毕设的那种)面对 break change(旧的API删除了,而你还在调用) 的报错可能是一脸懵逼的。简单概括的话,OpenCV 在不断剔除 C style 的 API,建议使用 CPP style 的 API。
比如,下面这种是 C style 的(一堆指针,每个方法前都带 cv):
IplImage *src;
src = cvLoadImage("lena.jpg");
cvNamedWindow("lena",CV_WINDOW_AUTOSIZE);
cvShowImage("lena",src);
cvWaitKey(0);
cvDestroyWindow("lena");
cvReleaseImage(&src);改成 CPP style 的,就会变成这样:
Mat img = imread("xx.jpg");
namedWindow("lena", CV_WINDOW_AUTOSIZE);
imshow("lena", img);
waitKey();在 C style 的方法中,我们要手动申请空间、释放内存和操作指针,在 CPP 中 class 会帮我们自动维护。如果你接到了师兄的老代码,在 OpenCV4.0 跑不了:
- 先查文档,找到修改后的数据类型
- 删掉旧代码方法前的 cv
- 声明和释放的时候手动修改一下
计算图优化
这部分的优化应该算是相互借鉴学习吧,OpenCV 也像 tensorflow 一样提供 lazy 的 API 了。我们可以把操作添加到计算图中,构建完整的计算图之后再同意执行(原来是立刻执行)。这样做的好处和 tensorflow 中的静态图也是一样的:图只需要编译一次就可以做重用或者并行优化。比如,原来我们这么写:
#include <opencv2/core.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
int main(int argc, char *argv[]) {
using namespace cv;
if (argc != 3) return 1;
Mat in_mat = imread(argv[1]);
Mat gx, gy;
Sobel(in_mat, gx, CV_32F, 1, 0);
Sobel(in_mat, gy, CV_32F, 0, 1);
Mat mag, out_mat;
sqrt(gx.mul(gx) + gy.mul(gy), mag);
mag.convertTo(out_mat, CV_8U);
imwrite(argv[2], out_mat);
return 0;
} 现在,我们可以把原来的 Sobel 操作变成 lazy 的 Sobel 操作,也就是 gapi::Sobel。在调用 gapi::Sobel 的时候,Sobel 不会立刻执行,直到 GComputation 才会整张计算图一起执行。
#include <opencv2/gapi.hpp>
#include <opencv2/gapi/core.hpp>
#include <opencv2/gapi/imgproc.hpp>
#include <opencv2/highgui.hpp>
int main(int argc, char *argv[]) {
using namespace cv;
if (argc != 3) return 1;
GMat in;
GMat gx = gapi::Sobel(in, CV_32F, 1, 0);
GMat gy = gapi::Sobel(in, CV_32F, 0, 1);
GMat mag = gapi::sqrt(gapi::mul(gx, gx) + gapi::mul(gy, gy));
GMat out = gapi::convertTo(mag, CV_8U);
GComputation sobel(in, out);
Mat in_mat = imread(argv[1]), out_mat;
sobel.apply(in_mat, out_mat);
imwrite(argv[2], out_mat);
return 0;
} DLDT 加速 OpenCV DNN
这部分 Intel 的大佬搞了很久了,现在对(英特尔的)CPU和(英特尔的,对,你没看错,报告都是在 Intel® HD Graphics 530 上测的)GPU 支持都很好。对于我们只关心训练速度不关心预测速度的科研狗而言,只需要知道传的参数就行了
Net net = readNet(model, config, framework);
net.setPreferableBackend(2);
// 0 代表自动
// 1 代表 halide
// 2 代表 DLDT
// 3 旧的 OpenCV DNN
net.setPreferableTarget(0);
// 0 代表 CPU
// 1 代表 OpenCL
// 2 代表 OpenCL fp16
// 3 代表 VPU令人有点遗憾的是,OpenCV 到了现在似乎都还不太关注训练(倒也不是完全不能用),可能是坚持走自己的路吧。OpenCV4.0 还有一些我不太关心的(小)改动,比如二维码生成和识别,ONNX导入之类的,这里就不详细介绍了。感觉这些功能没有很难受,有了觉得理所应当(逃
人脸识别
如果想要快速上手 OpenCV ,可以开发一个人脸识别系统 DEMO:从摄像头拍照,判断摄像头前的人是否在数据库中。整个过程基本分为 4 个部分,涉及了大部分 OpenCV 的基础 API:
1. 关键点检测(face detection)—— 使用 FMTCNN 模型得到人脸上关键点的位置
2. 人脸截取(face calibration)—— 根据关键点进行仿射变换,截取人脸图片
3. 特征提取(feature extraction)—— 使用 SphereFace 提取人脸特征
4. 识别结果(face classification)—— 使用相似度函数对比摄像头中的人脸特征和数据库中的人脸特征
从统计数据来看,似乎对 OpenCV 感兴趣的不很多(大家比较喜欢看调参的 233),因此这里就不再啰嗦实现过程了,如果有兴趣的话可以参照我的实现自己完成一个简单的 DEMO。
评论列表(0条)